Extracting Spotify Data with Spotipy

Spotify has a great API to give developers full access to all of the music data provided by the Spotify platform. In this article we'll use this api to scrap a playlist and enrich it with interesting song data.
In honor of the 60th Anniversary of the Billboard Hot 100 Singles chart, on August 4, 2018, they created this special chart of the 600 biggest songs of all time. Besides extracting these 600 songs from the Billboard, we'll also pull interesting song data such as danceability, loudness, energy of each song.
We'll use Spotipy library for scraping data from Spotify. Spotipy is a lightweight Python library for the Spotify Web API. With Spotipy we get full access to all of the music data provided by the Spotify platform.
Authentication
In order to authenticate with the Spotify Web API, we get a client ID and a client secret then keep the credentials in a .cfg file.
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
from configparser import ConfigParser
#retrieve the stored credentials
config = ConfigParser()
config.read('notebook.cfg')
client_id = config['spotify_api']['client_id']
client_secret = config['spotify_api']['client_secret']
#authenticate with Spotipy
client_credentials_manager = SpotifyClientCredentials(client_id = client_id, client_secret = client_secret)
#spotify object is created
sp = spotipy.Spotify(client_credentials_manager = client_credentials_manager)1. Playlist Items
Since playlist_items() function is limited to 100 tracks, we create a custom method to pull the related playlist data in the Top 600 Songs list.
# Playlist_tracks
def get_playlist_tracks(playlist_id):
pl_id = 'spotify:playlist:'+ playlist_id
offset = 0
print(pl_id)
while True:
response = sp.playlist_items(pl_id,
offset=offset,
fields='items(track(id,name,artists(name),album(name, album_type, release_date),popularity,duration_ms))'
)
if len(response['items']) == 0:
break
for item in response['items']:
yield(item["track"])
offset = offset + len(response['items'])
Then we use this method to pull the data from playlist_link, then store it in a pandas dataframe. (playlist_df)
playlist_link = 'https://open.spotify.com/playlist/0X9hkrRqCCP69Ze1MheAda'
playlist_id = playlist_link.split("/")[-1].split("?")[0]
track_list = []
for track in get_playlist_tracks(playlist_id):
track_id = track['id']
track_name = track['name']
artist_name = track['artists'][0]['name']
album = track['album']['name']
album_type = track['album']['album_type']
release_date = track['album']['release_date']
track_pop = track['popularity']
track_duration = track['duration_ms']
newlist = [track_id, track_name, track_duration, track_pop, artist_name, album, album_type, release_date ]
track_list.append(newlist)import pandas as pd
playlist_df = pd.DataFrame(track_list)
playlist_df.columns = ['track_id', 'track_name', 'duration', 'track_pop', 'artist', 'album', 'album_type', 'release_date']
Data transformation
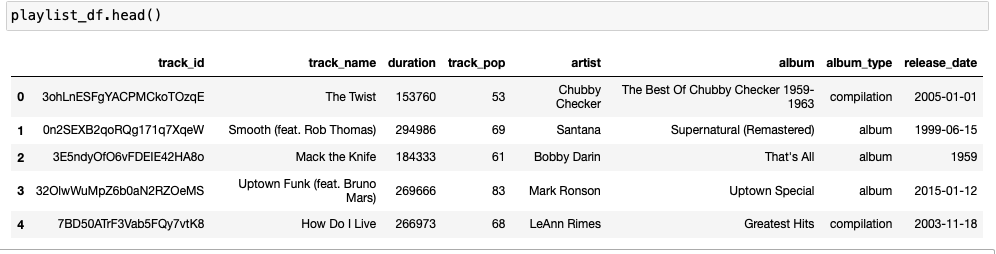
When we examine the first rows of the dataframe, we see that 'duration' column is in milliseconds. Thus we want to format it in seconds so that it can be easy-to-understand.
from datetime import timedelta
playlist_df['duration_sec'] = pd.to_timedelta(playlist_df.duration, unit='ms')
playlist_df.duration_sec = playlist_df.duration_sec.dt.total_seconds().astype(int)Another option is to convert 'duration' column to a easy-to-read format using datetime module.
playlist_df['duration'] = pd.to_datetime(playlist_df['duration'],
unit='ms').dt.strftime('%M:%S:%f').str[:5]
#reorder the columns
columns = ['track_id', 'track_name','track_pop', 'duration','duration_sec', 'artist', 'album', 'album_type', 'release_date']
playlist_df = playlist_df[columns]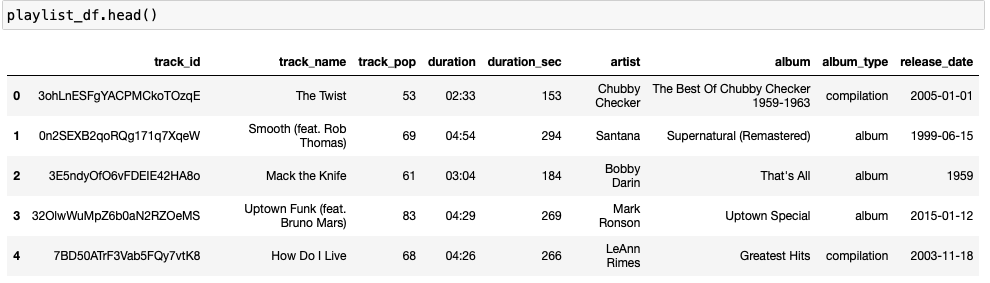
2.Track Audio Features
We'll pull the audio features data that corresponds to the track_id's in the track_list that we had formerly created.
track_ids = []
for track in track_list:
track_id = track[0]
track_ids.append(track_id)
len(track_ids)In the last line, we recheck if there are 600 tracks in our track list.
In order to pull the corresponding audio features data for the Top 600 Songs list, we'll use the audio_features() function.
audiofeatures_list = []
for track_id in track_ids :
features = sp.audio_features(track_id)[0]
danc = features['danceability']
enrg = features['energy']
key = features['key']
loud = features['loudness']
mode = features['mode']
spch = features['speechiness']
acou = features['acousticness']
inst = features['instrumentalness']
live = features['liveness']
valn = features['valence']
temp = features['tempo']
flist = [track_id, danc, enrg, key, loud, mode, spch, acou, inst, live, valn, temp]
audiofeatures_list.append(flist)After we put the selected audio features for each track to a list, we create the features_df dataframe.
features_df = pd.DataFrame(audiofeatures_list)
features_df.columns = ['track_id', 'danc', 'enrg', 'key', 'loud', 'mode', 'spch', 'acou', 'inst', 'live', 'valn', 'temp']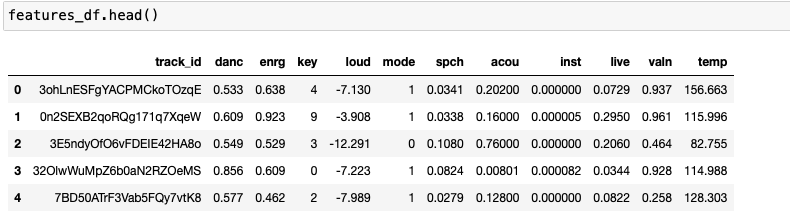
You can reach the code in my jupyter notebook from my github repository. I hope this gives you an idea about the workings of the Spotify Web API and Spotipy python library.